
我今天下午第一时间看到这个研究计划的时候,正在买东西,第一反应是:可惜了!
以下是我的愚蠢看法,各位请吐槽。
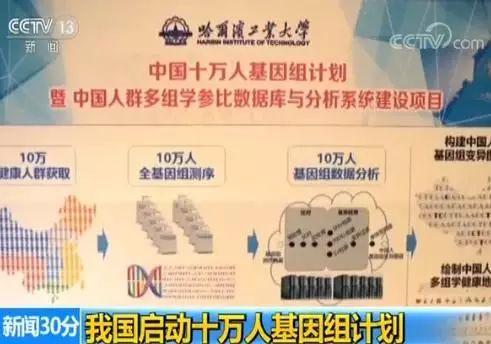
它应该算是目前国内 最有上层优势的一个大规模中国人群基因组研究项目——新闻里说的是首个重大国家计划。
但说实话,据我所知自十三五之后,国内这两年里并不乏这类研究项目。例如,福建厦门的基因大数据项目、江苏扬子国投的百万人群基因组项目,还有华大基因、诺禾致源、贝瑞和康、安诺优达等的各类大型基因科技公司所启动的大规模人群项目等少则几千,多则几十万,所以准确地说这个项目不是世界上最大规模的人类基因组计划(即便抛开国内的不讲,美国也早有百万人群,英国也早已启动10万人的基因组计划——GenomicEngland)。
但国内的这些项目,它们要么是在自下而上地推行着,要么就是组织较为松散复杂,利益不容易分配和平衡,说实话它们都很艰难。而那些自下而上推动的也很难有国家经费的支撑,只能靠企业自费研究。
今日宣布的这个“中国10万人基因组计划”,据我所知,应该是第一个上了央视的国字辈项目,这其实很了得,背后也有大科学家和院士领头。然而,很可惜的是,它的侧重点却是在健康人群队列上!
我并不是说,那样不对,只是在这 2-3年内一定有大几千、上万甚至几万的汉族人健康队列出来。所以在汉族人健康队列上,几年后它很可能会失去先发优势,科学价值可能不高了,从结果上看,最多就是跟风——我认为作为重大国家计划是应该会考虑科学的先发价值的。 当然作为医学和疾病研究的背景数据肯定依然有用——不管如何背景数据能够越多自然会越好。
样本数量越大虽然从结果看会越好。但其实是有边际效应的,越往后新增的样本能带来的新变异数量是会不断变少的,也就是说新样本带来的价值是在不断递减的。这是源自于同一祖先所致,特别是汉族人,这个人群内部的分化差异并不大! 所以过多的健康样本对这个群体来说意义不一定大。
我认为,有这个资源何不在搜集一定量的健康样本后,干脆集中精力研究一个/两个特定的疾病队列,那样是否更具有领先意义?
这个项目的推进速度是4年完成。按照目前国内的基因测序通量,虽然1年完成10万人的基因组测序没有问题,但前期的样本搜集应该要消耗不少时间,我臆测,包括搜集样本、知情同意和测序要花2年时间,然后2年完成所有分析。这个压力其实不小。所以后续进度如何拭目以待吧。
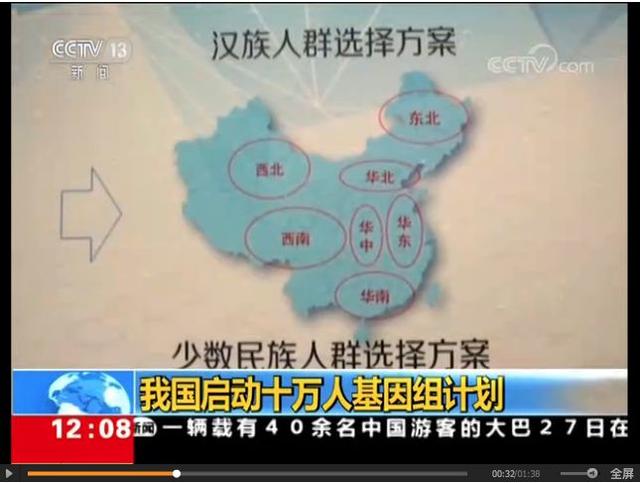
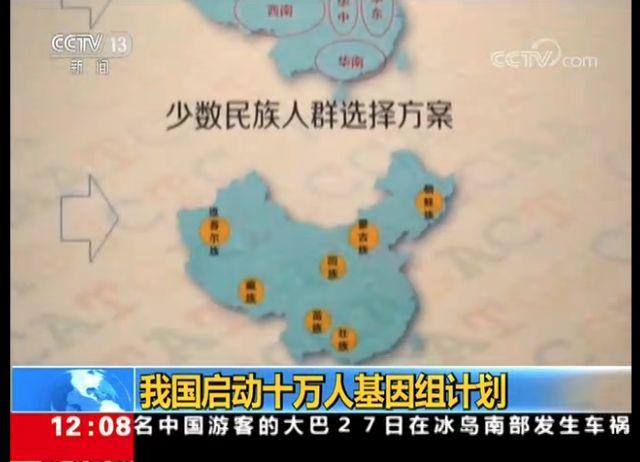
对于这个项目我觉得 唯一的看点是里面提到的9个少数民族,这是目前的空白,而且短时间内估计很难有其它项目能够填补这个空白。它对于广大少数民族同胞来说意义更大。而且,它对于我们如何更好地认识汉族人与少数民族之间的遗传差异和关系都有重要的价值。但不知到时具体样本数目是几何。
以上,便是我的愚见。
做点补充:对于纯粹健康人队列是不需要全部测高深度的,特别是样本量在万级以上的水平,这个在数学上是可以推算出来的,因此我认为是根本不需要每个样本测30x的。并且对于其中的汉族人,如果数目够多只需要测几层就够了(甚至是1x)。对于其中的少数民族,就看所取样量的多寡来适当区别对待。所以根本是不需要9000T(9Pb)的原始数据量的,而且如果中间步骤控制的好,中间数据的产出可以控制在原始数据的3倍以下,最终数据则更加会远少于原始数据量。如果是1x,那就是300T的数据量(如果保守点,多测一些,按倍数来乘),测序成本不会真的很高。而且,在joint calling之前,全部可以并行,按照这个数据量,现在通常的云计算平台是完全能够承受的,并不算多,解决方法也多。
本文首发于我的个人公众号:helixminer(碱基矿工)
