
思考这样一个问题:“RNAseq原始的Pair-end测序数据质控之后,部分Pair-end的read变成了Single-end的read,分开比对后得到了PE的BAM和SE的BAM,这个时候要不要合并这两个BAM文件?”
关于这个问题,我们在知识星球上对此进行过讨论。现在我总结一下我们的观点。
思考问题的熊:
这个问题可能需要多几个角度考虑。
- 为什么质控之后双端的reads变成了单端?一种可能是因为一端的read质控确实不合格,第二种情况(通常也是更常见的)是因为因为建库的原因,去接头之后两条reads overlap,从信息量来说就变成了单端,这个时候类似trimmomatic的软件就会默认把其中一条read当作无用read而扔掉。
- 通常来说,因为第一种情况而过滤掉的reads是相对少的,因此扔掉并无大碍,但是第二种就出问题了。目前大多数软件都不支持直接输入PE和SE的fastq文件进行mapping,你就必须把它分开做,这个时候你要是把单端的敢扔掉其实就是扔掉了大量的信息。
- 怎么解决这个问题呢?目前看来比较简单的方法是直接将trimmomatic的一个参数keepBothReads 改为true ,让因为第二种原因而扔掉的reads得以保留,然后直接用pair的fastq做mapping就可以了。
- 这个参数的影响可以看图

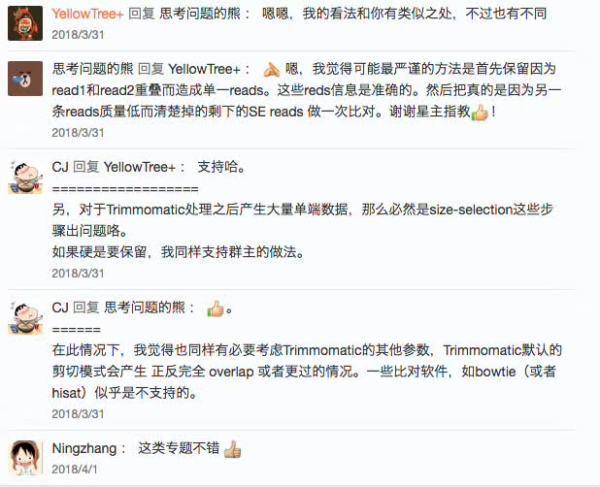
解螺旋的矿工(星球中的星主:YellowTree+):
RNAseq的数据在质控之后,有时候甚至会有多达10%的read会从Pair-end变为Single-End!!!丢掉的话,损失很大,所以要考虑留下来。我的看法和 @思考问题的熊 有相似之处,不过在处理Single-End的read上有些不同。我觉得可以这样做:
- 过滤后,Pair-end read和Single-End Read分开各自去完成比对,得到各自的比对结果(BAM格式);
- 分别计算PE的比对结果和SE比对结果在各个转录本上的覆盖数,然后把它们相加起来;
- 再用想在常用的基因表达分析工具(如EdgeR、DESeq等)进行下游分析;
这里在(2)中唯一要担心的是,有些SE Read覆盖的转录本也许不是最准确的那个(因为缺了另一半,你无法有效去判断),但我觉得这部分是少数,对结果不会有影响,这就是我认为可以分开比对,分别计算覆盖数再合并的原因。这样做的另一个好处是,不用太担心另一半低质量的Read误导了比对结果(不过可能这种情况也不会太多)——这也就是我和 @思考问题的熊 存在差异的地方,不过我觉得熊的看法的一个好处是,处理起来会更简单一些。
CJ
@YellowTree+, 支持哈。另,对于Trimmomatic处理之后产生大量单端数据,那么必然是size-selection这些步骤出问题咯。如果硬是要保留,我同样支持星主的做法。 @思考问题的熊,在此情况下,我觉得也同样有必要考虑Trimmomatic的其他参数,Trimmomatic默认的剪切模式会产生 正反完全 overlap 或者更过的情况。一些比对软件,如bowtie(或者hisat)似乎是不支持的。
矿工注解:
CJ在这里指的是ILLUMINACLIP参数的“keepBothReads”参数。这个参数很重要,它的作用是R1和R2在去除了接头序列之后,如果剩余的部分是完全反向互补的,其默认参数(false),会把整条与R1完全反向互补的 R2去除,当做重复去除掉,但在有些情况下,例如这里需要用到Paired reads的时候,就要将这个参数改为 true,否则会损失一部分Paired reads。
我举个例子,看一个 PE150 数据的测试,就知道 keepBothReads 参数的重要性了:
$ java -jar trimmomatic-0.36.jar PE -phred33 F-2-test_R1.fastq.gz F-2-test_R2.fastq.gz -baseout F-2.fastq.gz ILLUMINACLIP:TruSeq3-PE.fa:2:30:10 LEADING:3 TRAILING:3 SLIDINGWINDOW:4:15 MINLEN:51
ILLUMINACLIP: Using 1 prefix pairs, 0 forward/reverse sequences, 0 forward only sequences, 0 reverse only sequences
Input Read Pairs: 2500 Both Surviving: 1633 (65.32%) Forward Only Surviving: 828 (33.12%) Reverse Only Surviving: 12 (0.48%) Dropped: 27 (1.08%)
TrimmomaticPE: Completed successfully
# 使用 ILLUMINACLIP 默认的第六个参数 false,只有 65.32% paired reads 保留下来
$ java -jar trimmomatic-0.36.jar PE -phred33 F-2-test_R1.fastq.gz F-2-test_R2.fastq.gz -baseout F-2.fastq.gz ILLUMINACLIP:TruSeq3-PE.fa:2:30:10:8:true LEADING:3 TRAILING:3 SLIDINGWINDOW:4:15 MINLEN:51
ILLUMINACLIP: Using 1 prefix pairs, 0 forward/reverse sequences, 0 forward only sequences, 0 reverse only sequences
Input Read Pairs: 2500 Both Surviving: 2439 (97.56%) Forward Only Surviving: 22 (0.88%) Reverse Only Surviving: 16 (0.64%) Dropped: 23 (0.92%)
TrimmomaticPE: Completed successfully
# 将 ILLUMINACLIP 第六个参数改为 true,其余所有参数均相同,结果有 97.56% paired reads 保留下来
推荐阅读
欢迎关注我的个人公众号:helixminer(碱基矿工)

这是知识星球:解螺旋技术交流圈,是一个我与读者朋友们的私人朋友圈,欢迎你的加入。我有9年前沿而完整的生物信息学、NGS领域的工作经历,在该领域发有多篇Nature级别的科学文章。
这是知识星球上 第一个真正与基因组学和生物信息学强相关的圈子。我旨在营造一个高质量的组学知识圈和人脉圈,通过提问、彼此分享、交流经验、心得等,彼此更好地学习生信知识,提升基因组数据分析和解读的能力。
在这里你可以结识到全国优秀的基因组学和生物信息学专家,同时可以分享你的经验、见解和思考,有问题也可以向我提问和圈里的星友们提问。
知识星球邀请链接:「解螺旋技术交流圈」