
本周话题:全球十大主要基因组学项目盘点
下面这个图片,我之前单独分享过,是截至去年9月份的全球主要基因组学项目。
我这里主要盘点一下其中具有代表性的十个项目。
- 国际千人基因组(1000 Genome Project)项目

这是目前用得最广也是影响最大的一个国际联合基因组项目。2008年发起由英国Sanger研究所、美国 NHGRI 等多家科研机构共同发起的国际多人群基因组学项目,项目收集了全球26个不同群体2504个人的基因组数据,在2015年已经完成了第三期,自那之后几乎所有的人类基因组学研究成果都或多或少会使用里面的结果,贡献巨大。
该项目取得众多重要科研成果
- A global reference for human genetic variation Nature 526 68-74 2015
- An integrated map of structural variation in 2,504 human genomes Nature 526 75-81 2015
- An integrated map of genetic variation from 1,092 human genomes Nature 491 56-65 2012
- A map of human genome variation from population-scale sequencing Nature 467 1061-1073 2010
- 英国生物样本库(UK Biobank)项目
毫无疑问这个是当今世界上最大、影响力最高、制定标准最多的基因组科研项目,由英国独家主导,全球不少于2000个科研机构使用了它们的数据在进行科学研究,短短3年产出成果难以计算。
项目的目的是,建成世界上最大的有关致病或预防疾病的基因和环境因子的信息资源库,探索基因如何与人类生活方式及生活的环境相结合从而导致疾病,并旨在通过遗传学研究改善人类健康状况,并为全球科学界了解、诊断、治疗以及预防癌症、心脏病、糖尿病、关节炎、痴呆以及慢性肾病等重大疾病提供宝贵的数据资源,最终推动全球个体化医学的发展。
英国生物样本库(UK Biobank)这个项目其实在1999年就提起,这项研究计划在英国全国40至69岁人群中收集50万份志愿者(英国总人口的1%)的DNA样本,大规模搜集其基因信息样本、血缘数据和生活方式选择(包括营养,生活方式和药物使用等)。此外,志愿者提供了完善的个人健康信息,并同意英国生物样本库获取其国家卫生服务电子健康记录,跟踪记录他们的医疗档案资料。目前这个阶段已经完成了,而且数据开放度极大,全部数据(包括基因原始数据和医学临床数据等)可以研究者申请下载并用于自己的项目研究。今年(2020)还开放了 5 万人的全外显子基因数据——有 100TB 的原始数据,对于我们来说,下载这个量的数据在网速上是一个大问题。
另外,2018年英国卫生部长就发布的消息,进一步扩大这个项目,要在未来五年对500万个英国人基因组进行测序。注意,英国人口是6000万左右,所以差不多是十分之一的英国人,毫无疑问是迄今为止全球最大规模的科研与产业结合项目。总投入 30 亿英镑,预计 2025 年完成。
相关文章太多太多,不少于 3000 篇,大家在 PubMed 上搜索 UK Biobank 就知道了。
- 冰岛基因组计划(Genomes of Icelanders)

冰岛很特殊,它是一个远离大陆的岛屿,上面的人长期和大陆隔离,大致上可以认为是一个孤立的群体,他们有自己的遗传特点。研究这个群体对于认知特定疾病非常有帮助。
这个项目由冰岛deCODE genetics公司主持开展工作,其中illunima公司可是该项目的赞助方。2015年3月25日,冰岛deCODE genetics公司在《Nature Genetics》杂志上连发四篇文章,展示了有史以来在同一个人群中进行的最大规模全基因组测序研究。这项大规模测序项目向人们揭示了测序对于认识疾病的发生、生物多样性以及进化的深刻影响。项目使用2636个冰岛志愿者的全基因组以及104,220名冰岛人的 illunima 芯片数据。
这个项目的数据只有部分研究者可以使用。
已有四篇基因测序研究论文:
(1) Identification of a large set of rare complete human knockouts.
(2) Large-scale whole-genome sequencing of the Icelandic population.
(3) Loss-of-function variants in ABCA7 confer risk of Alzheimer’s disease.
(4) The Y-chromosome point mutation rate in humans.
- 欧洲百万基因组学计划
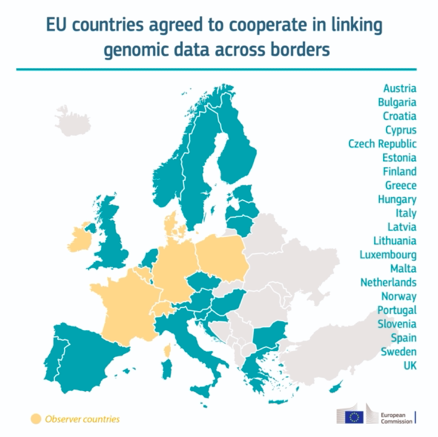
2019年8月发布欧洲百万基因组计划roadmap,项目包含欧洲21个国家, 成员国有奥地利,保加利亚,克罗地亚,塞浦路斯,捷克共和国,爱沙尼亚,芬兰,希腊,匈牙利,意大利,拉脱维亚,立陶宛,卢森堡,马耳他,荷兰,葡萄牙,斯洛文尼亚,西班牙,瑞典和英国以及2019年加入的挪威。
这个项目也向欧洲经济区和欧洲自由贸易协会的国家开放,是欧盟医疗与护理数字化转型议程的一部分。这项计划将改变欧洲健康研究和临床实践的游戏规则:共享更多的基因组数据将改善疾病的理解和预防,允许进行更多的个性化治疗(和针对性的药物处方),尤其是针对罕见疾病,癌症和与脑相关的疾病。
它们起步较晚,计划到2022年,完成在欧盟地区获得至少一百万个测序基因组的数据共享。目前也已经建立了数据库,包含了 15 万名志愿者的数据。
- 美国精准医学(ALL of US)项目

美国ALL of US多组学项目,是2015年奥巴马启动的美国精准医学项目。计划在十年之内投入15亿美元。自立项以来,All of Us项目的经费年年增长,2016年1.3亿美元,2017年2.3亿美元,2018年2.9亿美元。2018年开始收集样本,计划到2022年,整体的样本量达到100万。主要收集参与者的血液、唾液、尿液等样本,以及参与者的电子病历、生活习惯、居住环境等信息。参与者没有种族的限制,只要是合法的成年人(>=18岁)均可以自愿加入此项目。All of Us主要关注环境、个人习惯及遗传物质之间的互作,收集参与者的电子病例、血尿液样本、可穿戴设备数据及其它技术数据。对样本基因组进行测序,并分析它们与环境及生活习惯的互作。
All of Us主要由National Institutes of Health (NIH)负责,募集了100多个机构同时参与,主要构成有:生物样本中心、联络中心、数据存储及研究中心、健康支持组织、伙伴管理中心、自愿者技术支持中心及基因组分析团队。
- All of US项目经费年年增长,2016年1.3亿美元,2017年2.3亿美元,2018年2.9亿美元。2018年开始收集样本,计划到2022年,整体的样本量达到100万。
- 截至到2019年10月,已经有27万人参与者,收集了8万份电子医疗数据,21万份生物样本。
- 阶段性的成果发表在The NEW ENGLAND JOURNAL of MEDICINE(NEJM)上。
- 新加坡国家基因组(SG10K)项目
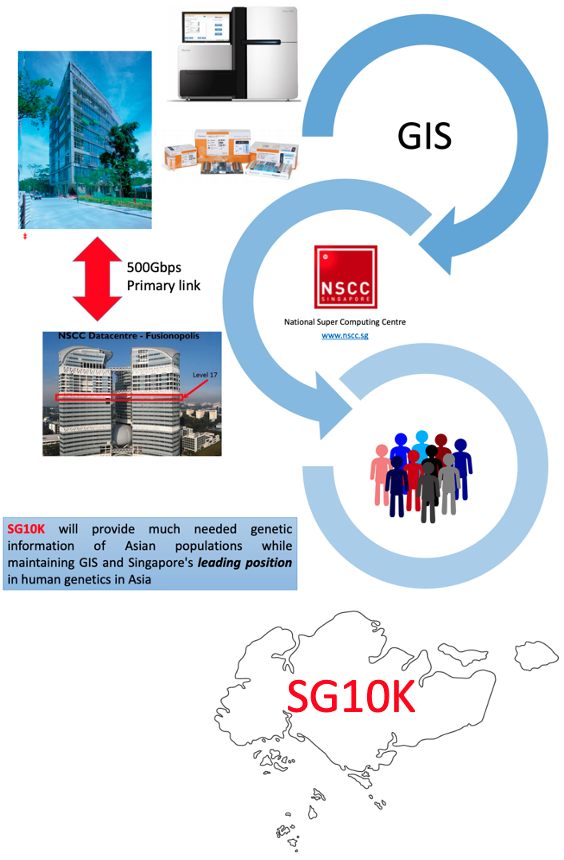
SG10K计划于2016年由新加坡的ATTRaCT平台(新加坡生物影像学联盟、新加坡基因组研究所、国家心脏研究中心等机构组成)牵头,联合多个研究机构开展启动,收集了包含新加坡华人、马来人、印度人3个本地群体的 10000 个样品,并对每个样品进行15X全基因组测序。该项目致力于构建新加坡人群的参考基因组及变异数据库,研究亚洲人群的迁移历史及精准医疗。
目前进展
研究人员已对4,810个样本测序分析,构建了亚洲人的变异信息数据库,探索了亚洲地区人群的迁移历史,相关的研究成果于2019年发表在《Cell》杂志上 ( https://doi.org/10.1016/j.cell.2019.09.019 )。
- 韩国蔚山万人基因组项目

2015年11月底,韩国蔚山国家科学技术研究所(UNIST)宣布推出韩国万人基因组计划,由韩国蔚山国家科学技术研究所主导,与哈佛医学院George Church教授主导的个人基因组计划(PGP)合作。该计划采集来自健康人群和免疫力低下人群的共一万份血液样本以及个人的临床信息,并计划在接下来几十年间,实现韩国全民基因组测序目标。
该计划是一个大规模的公共资助基因组计划,2016年获得150万美元的启动资金,资助机构包括蔚山市、巍山国家科学技术研究院、巍山大学医院、巍山大学等。预计到2019年,获得资助约2500万美元。
- 日本生物银行(BBJ)项目
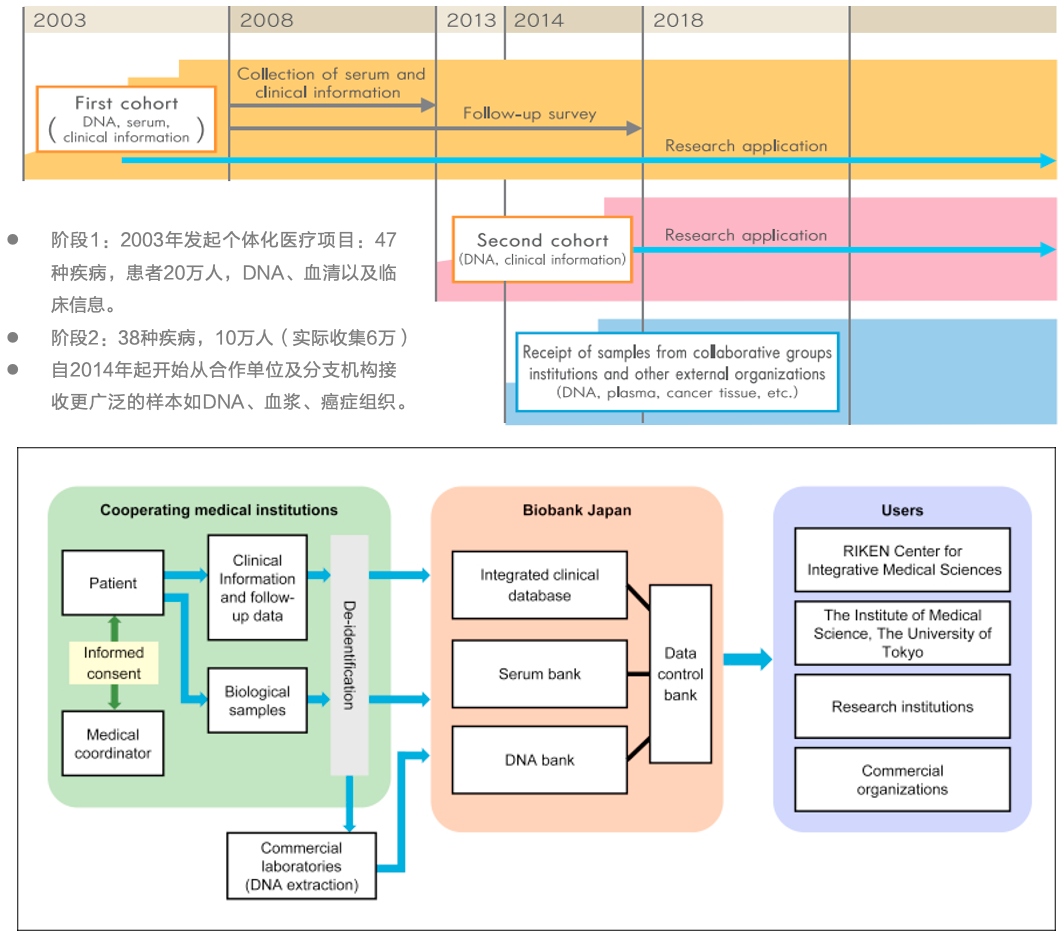
Biobank Japan是日本文部科学省(MEXT)的一个主要项目,旨在为个性化医疗的实施提供数据支持。截止2018年5月公布的数据,实现51种疾病覆盖,267,309人,441,557病例。在此大型数据基础上,相关的日本人基因组群体研究,以及疾病表型关联研究有大量产出。
项目研究内容主要是,2003年由日本文部科学省(MEXT)发起的个体化医疗项目(「ひとりひとりの体質に合った医療),收集了覆盖47种疾病的患者20万人的DNA、血清以及临床信息,形成初始队列。自2013年起个体化医疗项目进入新阶段,计划收集38种疾病,10万人,形成2期队列。现已于2013到2017年间收集患者6万人。自2014年起开始从合作单位及分支机构接收更广泛的样本如DNA、血浆、癌症组织。已收集的大样本大数据为基础,为相关基因与疾病表型的GWAS研究及日本人群体遗传学研究提供样本与数据支持,产出大量研究成果。
- 日本东北大学医学超级库项目

日本本土有两个大型基因组项目,除了上述 BBJ 之外,这也是其中一个。
日本东北大学东北医学超级库项目启动于2012年,拟建立先进的医疗系统来促进日本东北地区2011年大地震灾后重建工作。其10年计划蓝图主要包括三大部分:
(1)一个结合临床信息与基因组信息的生物样本数据库;
(2)整合医疗信息的在线平台;
(3)培养如生物信息研究人员等高层次技术人才和专家。
其生物样本数据库的特色在于研究与利用当地人群遗传信息,采用交叉学科的信息与通讯技术,建立基于基因组信息的医疗系统。
这个项目已经获得15万居民的知情同意,开展长期健康跟踪研究。包括两个队列:a、当地居民自然人群队列8万人;b、三世代(新生儿、父母、祖父母)队列7万人。主要包括部分队列人群的全基因组测序数据的分析,2013年11月发表了1000日本人全基因组参考数据集,并将持续增加样本规模至数千人。其发布的基因组参考是基因组与精准医学界的核心成果之一。该项目短期目标是检出低频变异,同时也将研究疾病发生机制、基因与环境互作等问题。并希望通过基因数据与持续问卷采集的表型信息、影像检查信息、蛋白质与小分子代谢产物的整合分析,构建疾病预防与治疗的新方法。
- 亚洲十万人基因组项目
该项目旨在创建亚洲人群的参考基因组,弥补亚洲人群基因组的缺失,并找出亚洲各人群的罕见和常见变异。项目牵头单位由韩国Macrogen公司、盆唐首尔大学医院精密医疗中心、新加坡南洋理工大学(NTU)、印度基因组分析企业MedGenome以及美国罗氏集团子公司Genentech组成。南洋理工大学教授Stephan Schuster作为科学主席,Mahesh Pratapneni作为执行主席,Rayman Mathoda作为共同执行主席。
在这个过程中,期望帮助理解疾病的生物学过程和发现新的治疗方案。项目分两个阶段,第一阶段先测1万人,找出人群的结构和分成。第二阶段再测9万人,同时收集临床的表型信息,来开展深度的疾病分析。该项目的基金伙伴可以获取队列个体的疾病和临床信息用来开展长期研究。
除了以上这十个之外,还有法国、丹麦、荷兰、印度2万人、泰国以及阿联酋全民基因组计划,对于我们国家来说,这一块还在追赶中。
文章和资讯
1、人造子宫
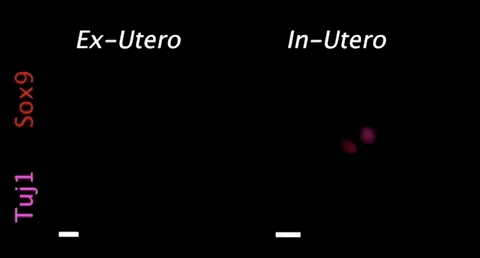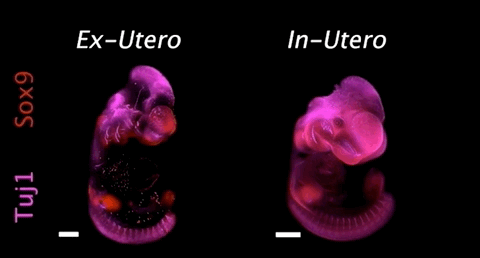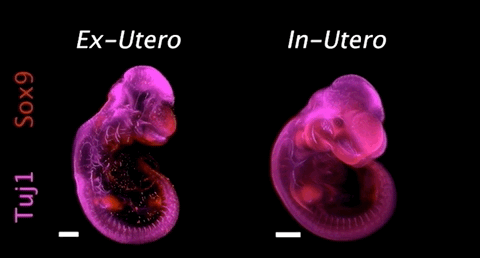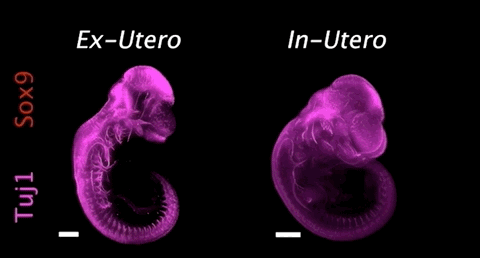
图:胚胎在人造子宫(左)和子宫(右)中发育对比(来源/Nature)
2021年3月17日,据生物世界报道,以色列魏茨曼科学研究所的 Jacob H. Hanna等人在 Nature 期刊在线发表研究论文。该团队创建了一个人造机器子宫,并首次使用人造子宫培养了小鼠胚胎6天时间(达到小鼠整个妊娠期的三分之一),且胚胎在人造子宫培育过程中发育正常。这项研究将为科研人员提供前所未有的工具,帮助了解基因编码的发育程序,提供有关出生缺陷和发育缺陷以及与胚胎植入有关缺陷的详细见解。
2、Science:基于古人类NOVA1基因培养出大脑类器官
2021年2月11日,加州大学圣迭戈分校的神经科学家Alysson Muotri团队,使用基因组编辑技术CRISPR–Cas9将古人类的NOVA1基因导入人多能干细胞内(多能干细胞能够发育成所有类型的细胞),然后他们将这些细胞培养成直径最大5毫米的大脑类器官。Nature对此发表了相关评论文章。
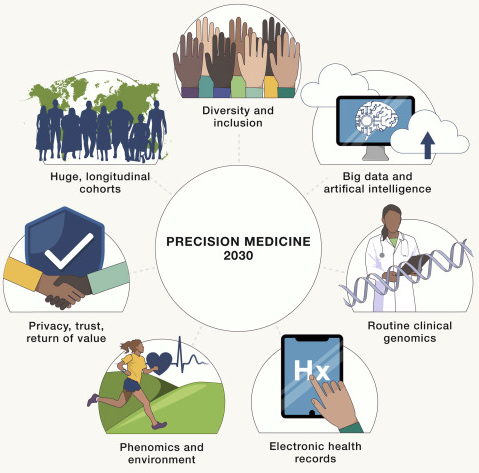
3、Cell:迈向2030年,精准医学的七大方向

近日,Cell期刊发布文章,指出迈向2030年,精准医学的七大方向:
1)通过国际大型纵向队列开放、共享和合作,充分挖掘群体数据;
2)提高生物医学研究中人群和科研者的多样性和包容性;
3)用大数据和人工智能,分析临床、分子和可穿戴设备等方面的数据;
4)临床基因组学辅助常见病和罕见病的预防、诊断和治疗成常态化;
5)电子健康档案将成为表型组和基因组研究的重要资源;
6)应用更加多样化、更高分辨率的表型组学和环境暴露数据;
7)通过建立信任、隐私保护和价值回馈机制,促进民众广泛参与
4、NEJM:临床全基因组测序可作为髓系肿瘤细胞遗传学分析替代方法
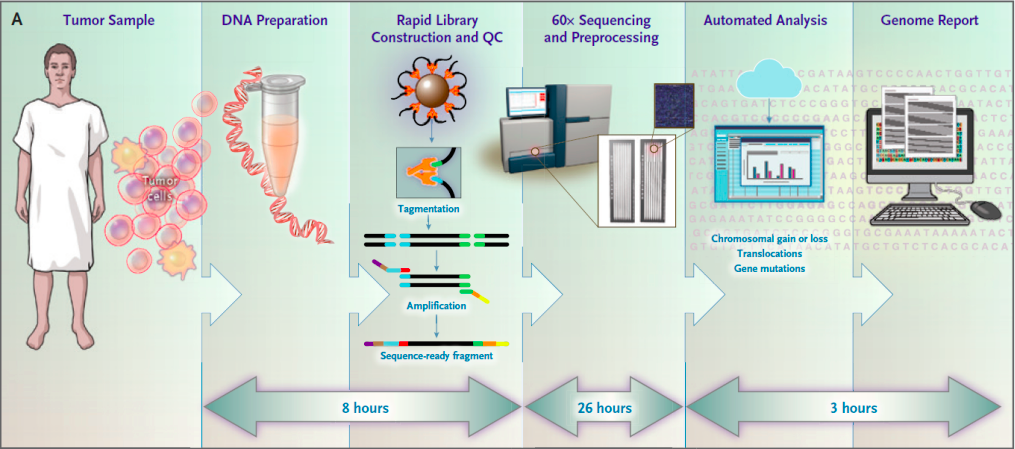
2021年3月11日,据测序中国报道,华盛顿大学医学院等单位的研究员在NEJM(《新英格兰医学》)上发表研究性文章,报道了一种对AML或MDS患者进行基因组特征分析的优化全基因组测序方法,并将其应用于临床样本。结果表明,与常规细胞遗传学分析相比,该方法的诊断敏感性相似或更佳,并且根据标准风险类别将患者进行风险分层的效率更高。
订阅
《碱基周报》每周首发于个人公众号:helixminer(碱基矿工)
